Conference: July 6, 2025
Meeting venue: The Second Lecture Hall on the first floor of the Mathematics Building, Jilin University
On-campus contact person:PeiJie Wang , [email protected]
Schedule:
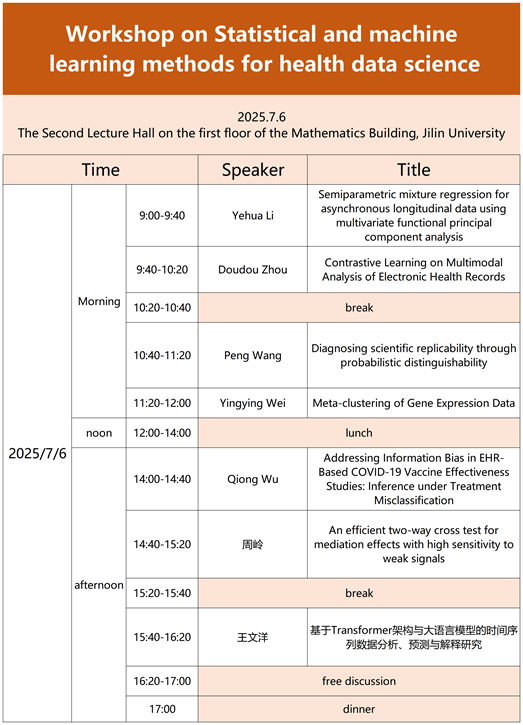
Workshop arrangement:
Semiparametric mixture regression for asynchronous longitudinal data using multivariate functional principal component analysis
Speaker: Yehua Li, Professor and Chair, Department of Statistics, UC-Riverside
Abstract:
The transitional phase of menopause induces significant hormonal fluctuations, exerting a profound influence on the long-term well-being of women. In an extensive longitudinal investigation of women’s health during mid- life and beyond, known as the Study of Women’s Health Across the Nation (SWAN), hormonal biomarkers are repeatedly assessed, following an asynchronous schedule compared to other error-prone covariates, such as physical and cardiovascular measurements. We conduct a subgroup analysis of the SWAN data employing a semiparametric mixture regression model, which allows us to explore how the relationship between hormonal responses and other time-varying or time-invariant covariates varies across subgroups. To address the challenges posed by asynchronous scheduling and measurement errors, we model the time-varying covariate trajectories as functional data with reduced-rank Karhunen-Lo ́eve expansions, where splines are employed to capture the mean and eigenfunctions. Treating the latent subgroup membership and the functional principal component (FPC) scores as missing data, we propose an Expectation-Maximization (EM) algorithm to effectively fit the joint model, combining the mixture regression for the hormonal response and the FPC model for the asynchronous, time-varying covariates. In addition, we explore data-driven methods to determine the optimal number of subgroups within the population. Through our comprehensive analysis of the SWAN data, we unveil a crucial subgroup structure within the aging female population, shedding light on important distinctions and patterns among women undergoing menopause.
About the Speaker:
Dr. Yehua Li is Professor and Chair of Statistics at the University of California, Riverside. He got his Ph.D. in Statistics in 2006 from Texas A&M University. Before joining UCR in 2018, he held faculty positions at the University of Georgia and Iowa State University. He is a Fellow of the American Statistical Association, a Fellow of the Institute of Mathematical Statistics, an Elected Member of the International Statistical Institute, and a recipient of the National Science Foundation CAREER Award in 2012. He has served on the editorial boards of the Canadian Journal of Statistics, the Journal of Multivariate Analysis, and Stat. His research interests include functional and longitudinal data analysis, non- and semi-parametric methods, spatial statistics, measurement error, mixture models, cardiovascular disease, and neuroimaging.
Contrastive Learning on Multimodal Analysis of Electronic Health Records
Speaker: Doudou Zhou, Assistant Professor, Department of Statistics, National University of Singapore
Abstract:
Electronic health record (EHR) systems contain a wealth of multimodal clinical data including structured data like clinical codes and unstructured data such as clinical notes. However, many existing EHR-focused studies has traditionally either concentrated on an individual modality or merged different modalities in a rather rudimentary fashion. This approach often results in the perception of structured and unstructured data as separate entities, neglecting the inherent synergy between them. Specifically, the two important modalities contain clinically relevant, inextricably linked and complementary health information. A more complete picture of a patient's medical history is captured by the joint analysis of the two modalities of data. Despite the great success of multimodal contrastive learning on vision-language, its potential remains under-explored in the realm of multimodal EHR, particularly in terms of its theoretical understanding. To accommodate the statistical analysis of multimodal EHR data, in this paper, we propose a novel multimodal feature embedding generative model and design a multimodal contrastive loss to obtain the multimodal EHR feature representation. Our theoretical analysis demonstrates the effectiveness of multimodal learning compared to single-modality learning and connects the solution of the loss function to the singular value decomposition of a pointwise mutual information matrix. This connection paves the way for a privacy-preserving algorithm tailored for multimodal EHR feature representation learning. Simulation studies show that the proposed algorithm performs well under a variety of configurations. We further validate the clinical utility of the proposed algorithm in real-world EHR data.
About the Speaker:
Dr. Doudou Zhou is an Assistant Professor at the Department of Statistics and Data Science, National University of Singapore. He obtained his Ph.D. in Statistics from the University of California, Davis, and completed his postdoctoral training at the Harvard T.H. Chan School of Public Health. His research interests include electronic health records, high-dimensional statistics, transfer learning, and federated learning. His work has been published in leading journals and conferences such as Journal of the American Statistical Association, Journal of Machine Learning Research, IEEE Transactions on Information Theory, and Conference on Learning Theory.
Diagnosing scientific replicability through probabilistic distinguishability
Speaker: Peng Wang, PhD Candidate in Mathematics, Jilin University
Abstract:
Despite the widely recognized importance of replicability in biological research, computational methods to quantify irreplicability and identify irreplicable instances remain underdeveloped. This paper presents an efficient and robust computational framework to address this gap. To tackle the challenge of defining an acceptable level of intrinsic heterogeneity among replicable studies, we introduce a distinguishability criterion, ensuring that replicable effects, while potentially heterogeneous, can be distinguished from zero effects and maintain consistent directions. We implement a Bayesian model criticism approach, reporting a Bayesian $p$-value to identify potential irreplicable instances. Through numerical experiments, we demonstrate the efficacy of the proposed methods in detecting batch effects in high-throughput experiments and identifying instances of the publication bias. Finally, we apply the framework to multi-tissue eQTL data from the GTEx consortium, uncovering tissue-specific eQTLs that represent genuinely irreplicable biological effects.
Meta-clustering of Gene Expression Data
Speaker: Yingying Wei, Associate Professor, Department of Statistics, Chinese University of Hong Kong
Abstract:
Traditional meta-analyses pool effect sizes across studies to improve statistical power. Likewise, there is growing interest in joint clustering across datasets to identify disease subtypes for bulk gene expression data and to discover cell types for single-cell RNA-sequencing (scRNA-seq) data. Unfortunately, due to the prevalence of technical batch effects, directly clustering of samples from multiple gene expression datasets can lead to wrong results. Therefore, in the past several years, there has been very active research on the integration of multiple gene expression datasets. However, the discussion on when multiple gene expression datasets can be integrated for joint clustering is lacking. Obviously, if different subtypes are assayed in distinct batches, then meta-clustering would be impossible no matter what types of machine learning or statistical methods are used. In this talk, I will present our
Batch-effects-correction-with-Unknown-Subtypes (BUS) framework. BUS is capable of adjusting batch effects explicitly, grouping samples that share similar characteristics into subtypes, identifying genes that distinguish subtypes and enjoying a linear-order computational complexity. The BUS framework can be adapted to perform meta-clustering for bulk gene expression data, scRNA-seq data collected from a single biological condition, and scRNA-seq data collected from multiple biological conditions, respectively. The proofs for model identifiability for the corresponding models provide insights on when multiple gene expression data can be integrated for meta-clustering and guidelines on experimental designs. Simulation studies and real data analyses show the advantages of our proposed models over state-of-the-art methods, especially when performing differential inference for scRNA-seq data collected from multiple conditions.
About the Speaker:
Yingying Wei is an Associate Professor in the Department of Statistics at the Chinese University of Hong Kong. She obtained her bachelor's degree in Mathematics from Tsinghua University and her Master’s degree (MSc Eng) in Computer Science and PhD degree in Biostatistics from Johns Hopkins University. She is interested in developing statistical methods for genomic, biomedical and social network data. She received the W. J. Youden Award in Interlaboratory Testing from the American Statistical Association in 2019.
Addressing Information Bias in EHR-Based COVID-19 Vaccine Effectiveness Studies: Inference under Treatment Misclassification
Speaker: Qiong Wu, Assistant Professor, Department of Biostatistics, University of Pittsburgh
Abstract:
Post-introduction evaluation of COVID-19 vaccines is essential to answer critical questions not fully addressed in clinical trials, such as effectiveness against evolving SARS-CoV-2 variants and the incidence of rare adverse events, and thus inform vaccine recommendations to the general public. However, in the U.S., the fragmentation of immunization records across multiple, often disconnected, systems results in incomplete vaccination histories in patients’ Electronic Health Records (EHRs). In this talk, I will first introduce a novel comparative effectiveness research (CER) pipeline leveraging the rank-preserving property of propensity scores and the integrated likelihood method to estimate effectiveness with misclassified treatments, in the absence of validation data. As the pandemic progressed, we achieved internal validation with reliable vaccination records by integrating EHR data with immunization information systems. Consequently, I will introduce the efficient influence function for average treatment effects in contexts where such internal validation is available. Following this, we construct an efficient estimator that achieves full statistical efficiency and has faster rates of convergence than estimating complex nuisance parameters. The proposed method is applied to data from a national network of U.S. pediatric medical centers (PEDSnet) to assess vaccination effectiveness among children and adolescents during the Omicron period.
About the Speaker:
Qiong is currently an assistant professor in the Department of Biostatistics and Health Data Science at the University of Pittsburgh. Her research interests include federated learning, transfer learning, and causal inference using real-world data, such as electronic health records (EHR) data, as well as complex-structured biomedical data, like neuroimaging data. Prior to her current position, she was a postdoctoral researcher in the Department of Biostatistics, Epidemiology, and Informatics (DBEI) at the University of Pennsylvania. She received her PhD degree from the University of Maryland in statistics.
An efficient two-way cross test for mediation effects with high sensitivity to weak signals
Speaker: 周岭,西南财经大学教授
Abstract:
The problem of hypothesis testing for mediation effects is of central interest in
mediation analysis. The key technical challenge pertains to the handling of composite null
hypotheses, without a priori knowledge of the true construct of the underlying mediation
pathway. Classical methods such as Sobel's test and MaxP test are overly conservative, and this
issue remains in existing bootstrap-based solutions and gets worse in the presence
of weak mediation effects. We propose a two-way cross-testing method along the line of
MaxP test, which is shown to enjoy both proper Type I error control and high power for
testing of weak mediation effects. The proposed test is scalable because it maintains the
same order of computational costs as the classical MaxP test. Theoretical investigations on
key large-sample properties such as asymptotic distributions, consistency, and Pitman's
efficiency are conducted. Extensive numerical evaluations on both simulated and real
datasets demonstrate the superiority of the proposed hypothesis testing method, and it
improves power over classical MaxP test as well as other existing tests. An R package
ctima implementing the proposed method is made available to the public.
About the Speaker:
周岭,西南财经大学教授,博导,曾荣获钟家庆数学奖,入选国家级青年人才。在非参数统计理论与应用、分布式/流数据增量学习、亚组学习等三方面取得系列研究成果,发表在JASA,AOSJRSSB等国际统计学,JMLR,ICML等计算机领域顶级期刊以及顶会上。现任Statistica Sinica等期刊副主编,国际统计学会(ISI)的Electedmember。主持国家自科面上、青年,作为主要参与人参与重点、科技部重大专项。
基于Transformer架构与大语言模型的时间序列数据分析、预测与解释研究
Speaker: 王文洋,大连海事大学副教授
Abstract:
随着人工智能技术的飞速发展,基于Transformer架构和大语言模型(LLM)的时间序列数据分析方法,正在推动科学与工业领域的数据驱动范式变革。本报告系统梳理并实证展示Transformer及其衍生大模型在复杂时序数据预测中的应用与创新。首先,针对甲醇等大宗化工产品价格波动的非平稳性与高波动性,提出生成式预训练甲醇价格预测模型(CEGPT-PF-M),通过迁移学习和私有数据库微调,实现对多源异构时序数据的高效整合与精准预测。其次,针对航运市场多类型船舶价格预测难题,构建具备稀疏注意力机制的Transformer模型——SPPformer,通过多领域预训练与行业数据微调,显著提升模型在干散货、集装箱、油轮等市场的泛化能力与效率。两类模型均引入SHAP方法,实现了特征变量对预测结果的可视化解释,增强模型决策透明度。实证结果表明,基于Transformer的大模型在预测准确性、稳定性、可扩展性和可解释性方面均大幅优于传统统计与机器学习方法。相关研究为多产业提供科学决策工具,也为复杂工业时序数据的智能分析与预测开辟新路径。
About the Speaker:
王文洋,男,博士,大连海事大学副教授。2014年获得大连理工大学信息与计算科学学士学位,2016年获得密苏里大学应用统计学硕士学位,2020年获得密苏里大学统计学哲学博士学位,2022—2024年于中国科学院从事博士后研究工作。入选大连市高层次人才、大连市城市发展紧缺人才、大连市兴连人才计划和辽宁省“兴辽人才计划”储备人才。主要研究方向为大数据分析、机器学习、人工智能和大模型。近五年主持/参与机器学习、大数据分析、大语言模型方向的国家与省部级课题10余项,以第一作者/通讯作者身份发表SCI、SSCI索引论文20余篇,出版教材1部。







